利用pandas做数据分析统计应用---统计二胎年龄差距
本文共 918 字,大约阅读时间需要 3 分钟。
源码和数据文件见上述链接。
本文数据提取自深圳市2019年某次公租房申请公示名单,移除了非身份证的数据。
import pandas as pdimport matplotlib.pyplot as plt '''粗略统计二胎年龄差距se 为1 主申请人,多数为爸爸se为2共同申请人,多为妈妈和孩子se为0,others'''#difage = []class family: def __init__(self): self.mainpyear= None self.comPyear=[] self.diff = [] def diff_age(self): if len(self.comPyear)>2: self.comPyear = sorted(self.comPyear, reverse = True) #print(self.comPyear) if( self.comPyear[0]-self.comPyear[1]<18): self.diff.append( self.comPyear[0]-self.comPyear[1]) self.comPyear=[]if __name__ == '__main__': b= pd.read_csv('a.csv', sep=',', dtype = {'id':str}) b['year']=pd.to_numeric(b['id'].str[6:10]) myf = family() for key,row in b.iterrows(): if( row['se']==1): myf.mainpyear = row['year'] myf.diff_age() elif( row['se']==2): myf.comPyear.append(row['year']) #myf.diff_age() #print(myf.diff) a = pd.Series(myf.diff) a.plot.hist(bins =19 ) plt.show() 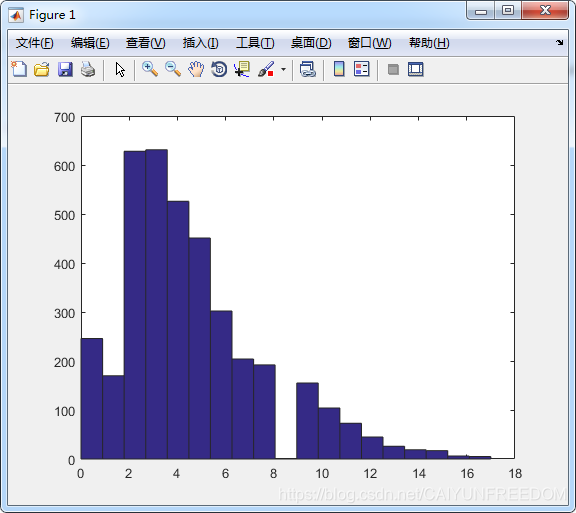
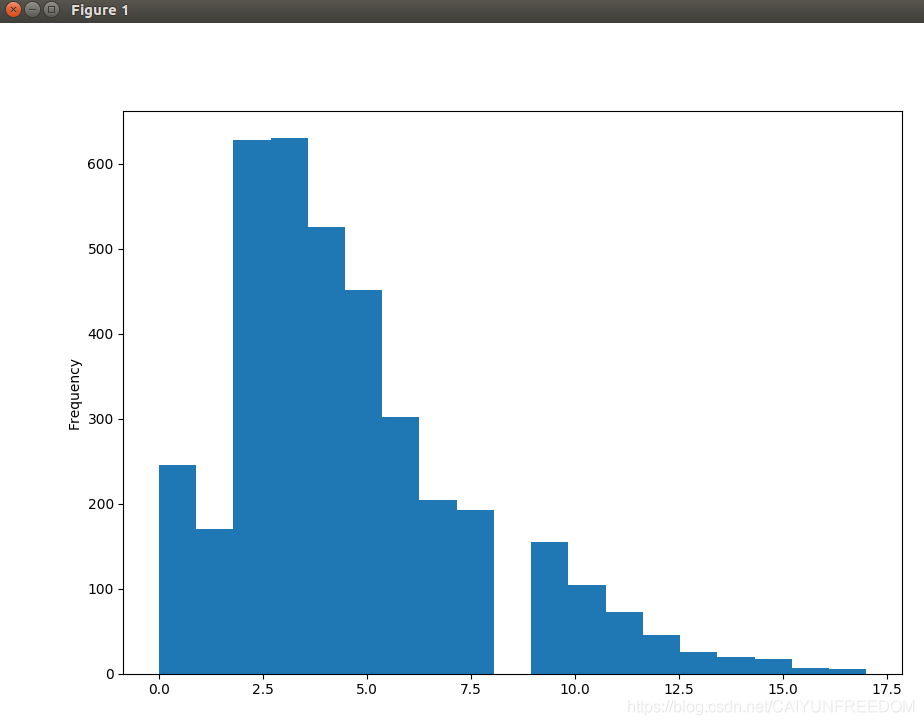
结论:二胎年龄差距,2,3岁的家庭最多。
转载地址:http://tfpg.baihongyu.com/
你可能感兴趣的文章
ms sql server 2008 sp2更新异常
查看>>
MS UC 2013-0-Prepare Tool
查看>>
msbuild发布web应用程序
查看>>
MSCRM调用外部JS文件
查看>>
MSEdgeDriver (Chromium) 不适用于版本 >= 79.0.313 (Canary)
查看>>
msf
查看>>
MSSQL数据库查询优化(一)
查看>>
MSSQL日期格式转换函数(使用CONVERT)
查看>>
MSTP多生成树协议(第二课)
查看>>
MSTP是什么?有哪些专有名词?
查看>>
Mstsc 远程桌面链接 And 网络映射
查看>>
Myeclipse常用快捷键
查看>>
MyEclipse用(JDBC)连接SQL出现的问题~
查看>>
myeclipse的新建severlet不见解决方法
查看>>
MyEclipse设置当前行背景颜色、选中单词前景色、背景色
查看>>
MyEclipse配置SVN
查看>>
MTCNN 人脸检测
查看>>
MyEcplise中SpringBoot怎样定制启动banner?
查看>>
MyPython
查看>>
MTD技术介绍
查看>>